MONDAY: 1 August 2022. Afternoon paper. Time Allowed: 3 hours.
This paper has two sections. SECTION I has twenty (20) short response questions of forty (40) marks. SECTION II has three (3) practical questions of sixty (60) marks. All questions are compulsory. Marks allocated to each question are shown at the end of the question.
SECTION I
1. ____________________ is a big data dimension reduction technique used to reduce the dimensionality of large data sets, by transforming a large set of variables into a smaller set that still contains most of the information in the large set. (2 marks)
2. The _______________ learning, is an area of machine learning concerned with how agents ought to take actions in an environment to maximise some notion of cumulative reward. (2 marks)
3. A deep learning neural network designed for processing structured arrays of data such as images is called __________. (2 marks)
4. _________is an umbrella term used to describe datasets that cannot reasonably be handled by traditional computers or tools due to their volume, velocity, and variety. (2 marks)
5. The data pre-processing technique that is used for handling missing values in dataset by use of statistical metrics is known as data ____________. (2 marks)
6. You have been tasked as the data scientists to develop a machine learning model for a supermarket that determine the two products customers purchase together. The ____________ algorithm is the best algorithm to carry out this task. (2 marks)
7. In social network analysis, ___________ is the metric used to measure how quickly an entity can access more entities in a network (2 marks)
8. In a decision tree classification algorithm, all nodes except the root node are called leaf nodes. True or False? (2 marks)
9. When collecting data for analytics from participants, it is significant to give participants a reasonable and accurate understanding of how their data will be used. This is called _____________. (2 marks)
10. In Natural Language Processing (NLP), eliminating affixes from a word such as “eating to eat” is called ___________, as used in machine learning tasks focused on human languages. (2 marks)
11. The _______________ network can be simply expressed as an information processing system designed to imitate the human brain structure and functions based on its source, features, and explanations. (2 marks)
12. Identify the name given to the data visualisation technique shown below? (2 marks)

13. The data structure made up of connection of nodes and edges, used data analytics for in fraud detection is called a _____________? (2 marks)
14. The big data process of reviewing and revising data in order to delete duplicates, correct errors and provide consistency is known as? (2 marks)
15. The _________________regression model is used to solve classification problems in machine learning. (2 marks)
16. The activation function used in machine learning to transform the output of fully connected layer into a probability distribution of values which adds up to one is known as _______________. (2 marks)
17. Given, import numpy as np, type a statement to Convert the python list, my_list = [1,2,3], into a single dimensional numpy array, without creating any spaces. (2 marks)
18. The artificial intelligence technique where large amount of data from an unlabeled dataset is divided into multiple categories according to internal similarity of the data and data in the same category is more similar than that in different categories is called? ______________. (2 marks)
19. The clusters obtained in k-means meet the following conditions: (1) Objects in the same cluster are dissimilar (2) The similarity of objects in different clusters is high. True or False? (2 marks)
20. Consolidation of data from different sources into one unified hub, such as a data warehouse, so that users have centralised access to all the information they need for data mining, business intelligence reporting, and operational purposes is known as data _______________ (2 marks)
SECTION II
21. Create a word processing document named “Question 21” use the word processor document to save your answers to questions 1 to 8 in form of screenshots.
Type the following dataset into excel document. Create a folder in drive C: and name it AnalyticsAug.
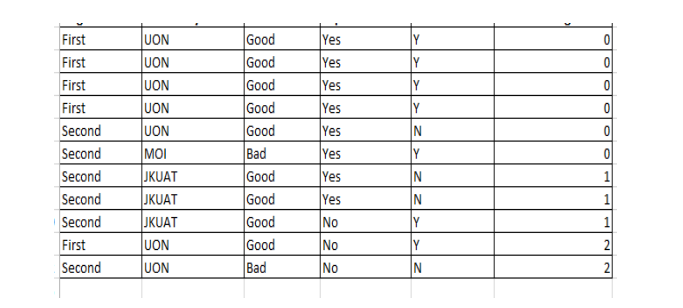
Required:
1. Save the excel document in AnalyticsAug folder as a comma separated version (CSV) file and name it Colleges.csv. (3 marks)
2. State python code to import the necessary python libraries. (3 marks)
3. Key in python code to extract data from the source and print the output. (3 marks)
4. State python code to transform the data into a numeric array and print the output. (3 marks)
5. Type python code to separate independent variables from dependent variable and print the output. (3 marks)
6. Explain the python code you would use to normalise the data and print the output. (3 marks)
7. Explain how you would apply K-means algorithm to create clusters. (3 marks)
8. State python code to visualise the generated clusters. (4 marks)
Upload Question 21 document.
(Total: 25 marks)
22. Create a word processing document named “Question 22” use the word processor document to save your answers to questions 1 to 8 in form of screenshots.
1. Type the following dataset into excel document. Create a folder in drive C: and name it Studentsdata. Save the excel document in Studentsdata folder as a comma separated version (CSV) file and name it Assignmentmarks.csv. (3 marks)
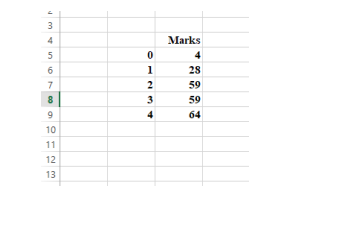
2. Write python code that loads data from the .csv file, prints the entire data, then computes and print the measures of central tendency. (5 marks)
3. Write python code that will print the minimum mark, the maximum mark then, calculate and print the range. (3 marks)
4. Write python code that will calculate and print the interquartile range. (5 marks)
5. Write python code that will calculate and print the standard deviation and variance of the marks. (4 marks)
Upload Question 22 document.
(Total: 20 marks)
23. Create a word processing document named “Question 23” use the word processor document to save your answers to
questions 1 to 4 in form of screenshots.
1. Type the following dataset into excel document. Create a folder in drive C: and name it Patientsdata. Save the excel document in Patientsdata folder as a comma separated version (CSV) file and name it Patientsweight.csv. (3 marks)
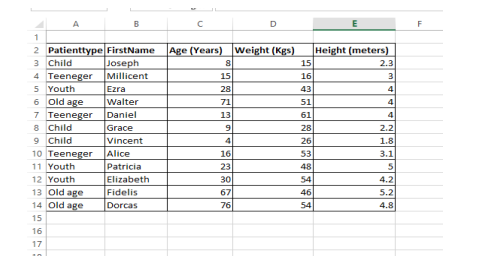
2. Write python code that will find and print the average weight of all the patients by patient type. (4 marks)
3. Write python code that will group the unique values from the patient column. (4 marks)
4. Write python code that will find the mean of the height column for each patient group. (4 marks)
Upload Question 22 document.
(Total: 15 marks)